|
Keren Gruteke Klein Hi! I'm a PhD candidate in Data Science at the Technion, advised by Yevgeni Berzak in the Language, Computation and Cognition (LaCC) Lab. My research lies at the intersection between Natural Language Processing and Cognition, focusing on cognitively driven readability and text simplification, and the generation of eye-movement scanpaths during reading. I co-develop EyeBench, a benchmark for predictive modeling from eye movements in reading. LinkedIn / GitHub / Scholar / ORCID 💬 Contact me at: gkeren[at]campus.technion.ac.il |

|
📚 Publications |
|
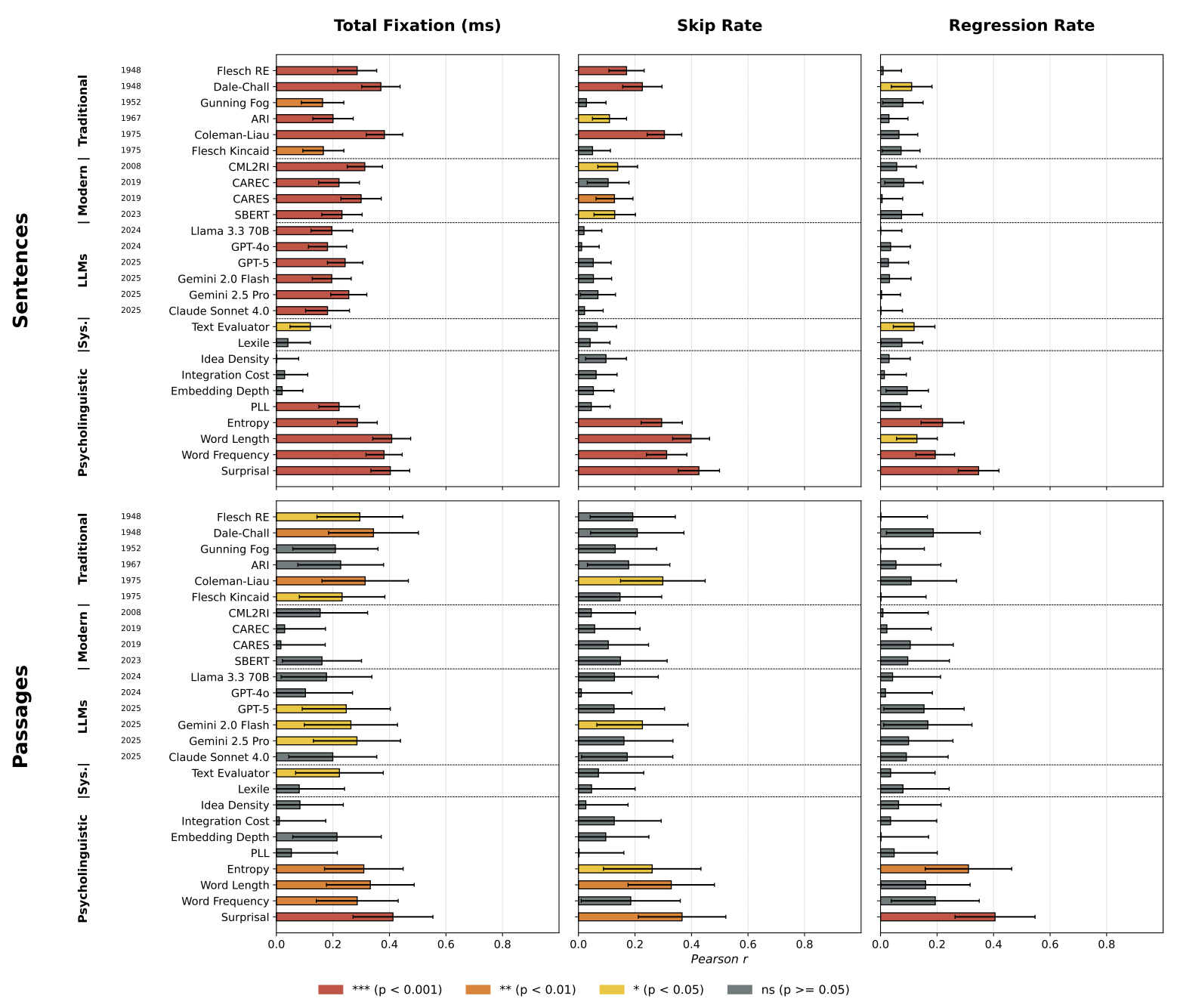
Readability Formulas, Systems and LLMs are Poor Predictors of Reading Ease
K. Gruteke Klein, S. Frenkel, O. Shubi, Y. Berzak Under review, 2025 PDF / arXiv / Cite Methods for scoring text readability have been studied for over a century, and are widely used in research and in user-facing applications in many domains. Thus far, the development and evaluation of such methods have primarily relied on two types of offline behavioral data, performance on reading comprehension tests and ratings of text readability levels. In this work, we instead focus on a fundamental and understudied aspect of readability, real-time reading ease, captured with online reading measures using eye tracking. We introduce an evaluation framework for readability scoring methods which quantifies their ability to account for reading ease, while controlling for content variation across texts. Applying this evaluation to prominent traditional readability formulas, modern machine learning systems, frontier Large Language Models and commercial systems used in education, suggests that they are all poor predictors of reading ease in English. This outcome holds across native and non-native speakers, reading regimes, and textual units of different lengths. The evaluation further reveals that existing methods are often outperformed by word properties commonly used in psycholinguistics for prediction of reading times. Our results highlight a fundamental limitation of existing approaches to readability scoring, the utility of psycholinguistics for readability research, and the need for new, cognitively driven readability scoring approaches that can better account for reading ease. |
|
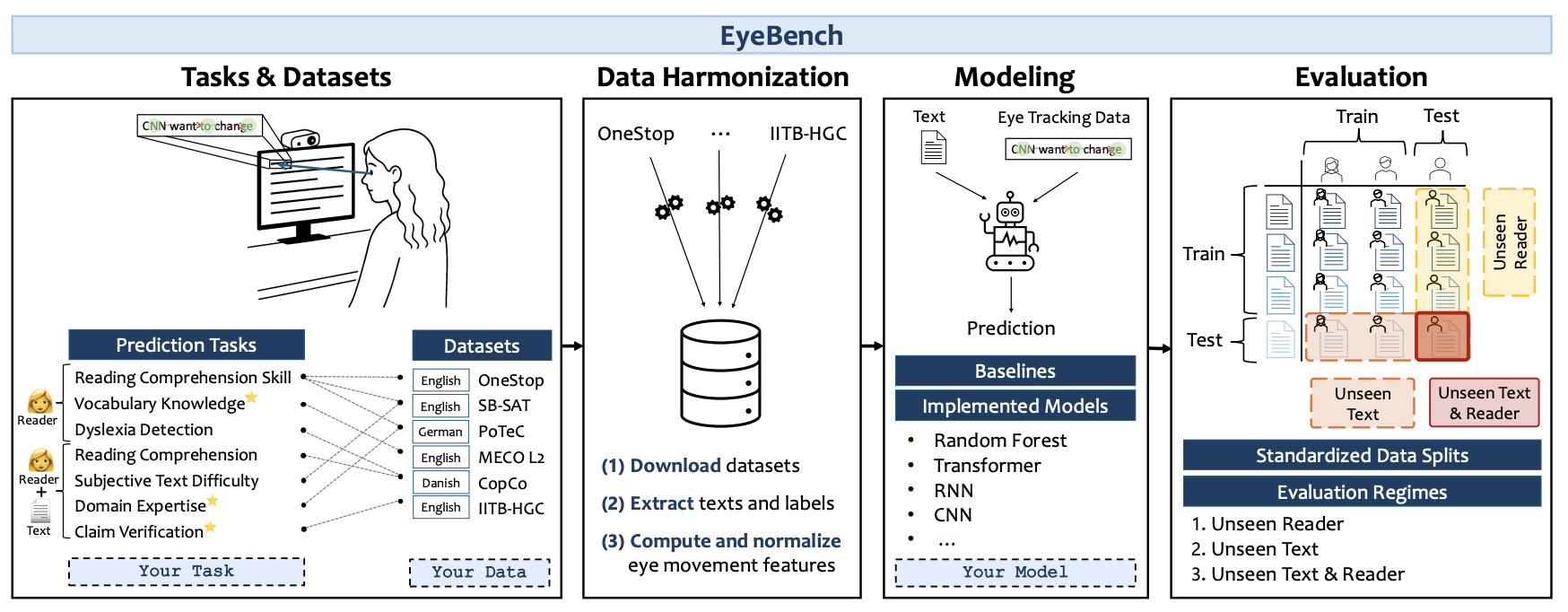
EyeBench: Predictive Modeling from Eye Movements in Reading
O. Shubi, D. R. Reich, K. Gruteke Klein, Y. Angel, P. Prasse, L. A. Jäger, Y. Berzak NeurIPS, 2025 Benchmark Project Page / Cite We present EyeBench, the first benchmark designed to evaluate machine learning models that decode cognitive and linguistic information from eye movements during reading. EyeBench offers an accessible entry point to the challenging and underexplored domain of modeling eye tracking data paired with text, aiming to foster innovation at the intersection of multimodal AI and cognitive science. The benchmark provides a standardized evaluation framework for predictive models, covering a diverse set of datasets and tasks, ranging from assessment of reading comprehension to detection of developmental dyslexia. Progress on the EyeBench challenge will pave the way for both practical real-world applications, such as adaptive user interfaces and personalized education, and scientific advances in understanding human language processing. The benchmark is released as an opensource software package which includes data downloading and harmonization scripts, baselines and state-of-the-art models, as well as evaluation code, publicly available at https://github.com/EyeBench/eyebench. |
|
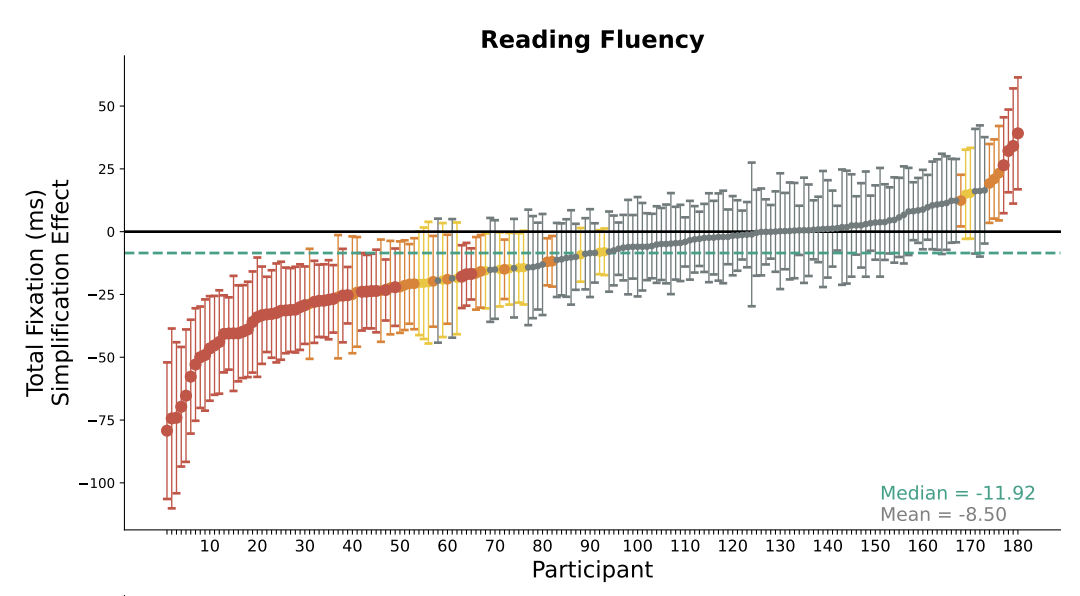
The Effect of Text Simplification on Reading Fluency and Reading Comprehension in L1 English Speakers
K. Gruteke Klein, O. Shubi, S. Frenkel, Y. Berzak CogSci, 2025 Oral PDF / Paper / Cite Text simplification is a common practice for making texts easier to read and easier to understand. To which extent does it achieve these goals, and which participant and text characteristics drive simplification benefits? In this work, we use eye tracking to address these questions for the first time for the population of adult native (L1) English speakers. We find that 42% of the readers exhibit reading facilitation effects, while only 2% improve reading comprehension accuracy. We further observe that reading fluency benefits are larger for slower and less experienced readers, while comprehension benefits are more substantial in lower comprehension readers, but not vice versa. Finally, we find that high-complexity original texts are key for enhancing reading fluency, while large complexity reduction is more pertinent to improving comprehension. Our study highlights the potential of cognitive measures in the evaluation of text simplification and distills empirically driven principles for enhancing simplification effectiveness. |
|
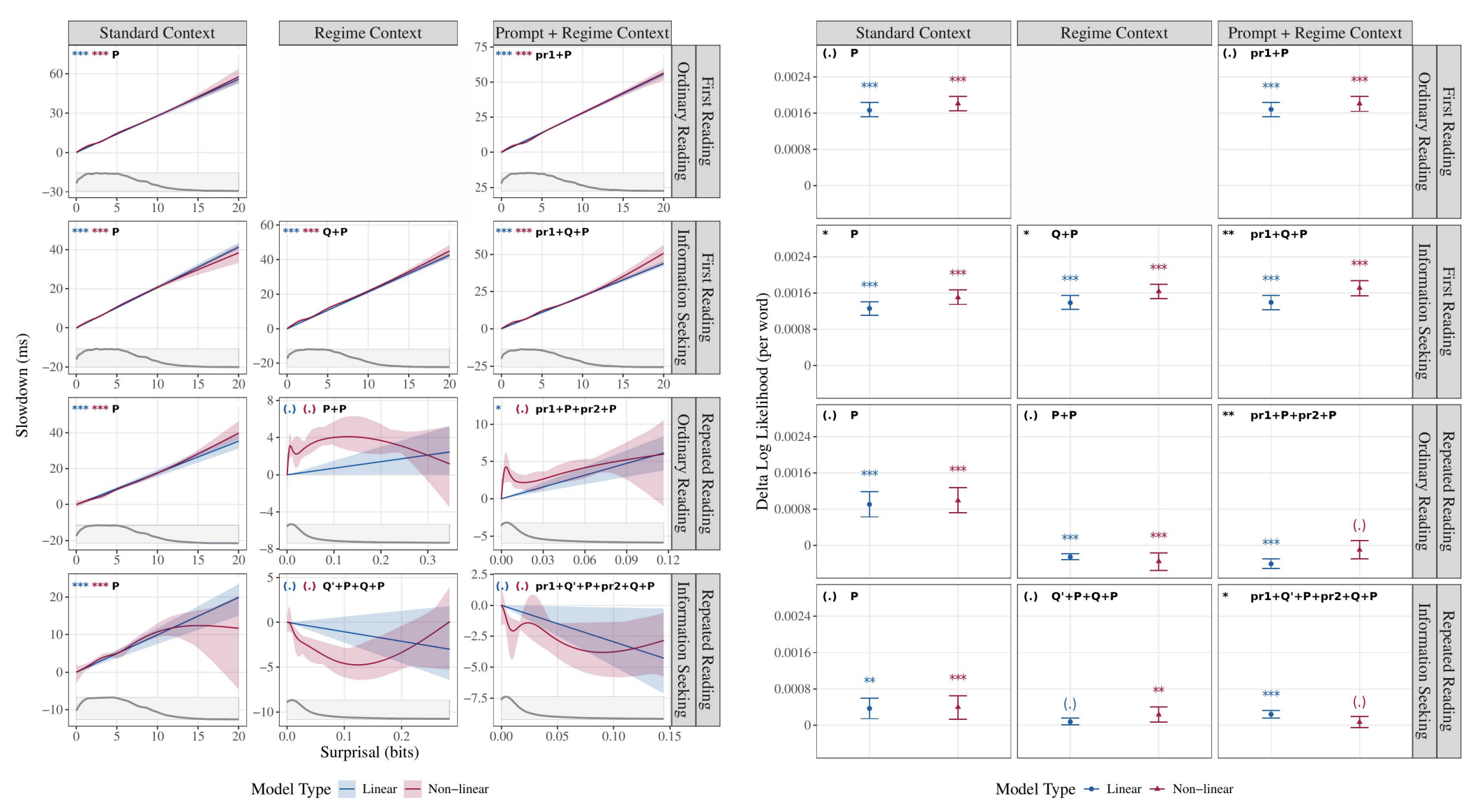
The Effect of Surprisal on Reading Times in Information Seeking and Repeated Reading
K. Gruteke Klein, Y. Meiri, O. Shubi, Y. Berzak CoNLL, 2024 Oral 20% acceptance PDF / Paper / Cite The effect of surprisal on processing difficulty has been a central topic of investigation in psycholinguistics. Here, we use eyetracking data to examine three language processing regimes that are common in daily life but have not been addressed with respect to this question: information seeking, repeated processing, and the combination of the two. Using standard regimeagnostic surprisal estimates we find that the prediction of surprisal theory regarding the presence of a linear effect of surprisal on processing times, extends to these regimes. However, when using surprisal estimates from regimespecific contexts that match the contexts and tasks given to humans, we find that in information seeking, such estimates do not improve the predictive power of processing times compared to standard surprisals. Further, regime-specific contexts yield near zero surprisal estimates with no predictive power for processing times in repeated reading. These findings point to misalignments of task and memory representations between humans and current language models, and question the extent to which such models can be used for estimating cognitively relevant quantities. We further discuss theoretical challenges posed by these results. |
Talks & Presentations
|
Bio🎓 Education.
🏆 Awards. VATAT Scholarship for Outstanding MSc Students. 💼 Industry. Data Scientist at Wiliot (2022–2024). 👩🏫 Teaching.
|
Last updated: Nov 2025 · © Keren Gruteke Klein · Feel free to get in touch.